数据库知识点总结
MySQL
SQL的join
select column_name(s)
from table 1
INNER JOIN table 2
ON
table 1.column_name=table 2.column_name
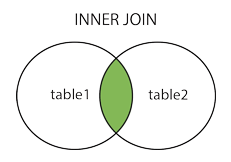
INNER JOIN产生的结果集中,是1和2的交集。

LEFT JOIN产生表1的完全集,而2表中匹配的则有值,没有匹配的则以null值取代。

RIGHT JOIN产生表2的完全集,而1表中匹配的则有值,没有匹配的则以null值取代。
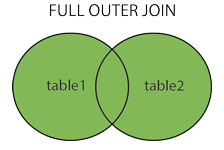
FULL OUTER JOIN产生1和2的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。
ACID
- 原子性(Atomicity): 操作要么全部完成,要么全部回滚。
- 一致性(Consistency): 事务使数据库的一个一致性状态变为另一个一致性状态,事务执行不改变数据库一致性。
- 隔离性(Isolation): 多用户事务并发访问事务之间隔离。
- 持久性(Durability): 持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的。
四个隔离级别
- Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
- Repeatable read (可重复读):可避免脏读、不可重复读的发生。
- Read committed (读已提交):可避免脏读的发生。
- Read uncommitted (读未提交):最低级别,任何情况都无法保证。
脏读、幻读、不可重复读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
SQL: on
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
SQL优化
- 选取最适用的字段属性,尽量把字段设置为NOTNULL
- 使用连接(JOIN)来代替子查询(Sub-Queries),连接(JOIN)..之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
- 使用联合(UNION)来代替手动创建的临时表
- 使用索引,一般说来,索引应建立在那些将用于JOIN,WHERE判断和ORDERBY排序的字段上。尽量不要对数据库中某个含有大量重复的值的字段建立索引。对于一个ENUM类型的字段来说,出现大量重复值是很有可能的情况,在建有索引的字段上尽量不要使用函数进行操作。
InnoDB与MyISAM区别
- InnoDB支持外键,MyISAM不支持
- InnoDB支持行锁,MyISAM不支持
- MyISAM支持全文搜索
- InnoDB支持事务处理
- InnoDB跨平台可以直接拷贝,MyISAM不支持
- InnoDB表很难被压缩,MyISAM可以被压缩
选择: 因为MyISAM相对简单所以在效率上要优于InnoDB.如果系统读多,写少。对原子性要求低。那么MyISAM最好的选择。且MyISAM恢复速度快。可直接用备份覆盖恢复。
如果系统读少,写多的时候,尤其是并发写入高的时候。InnoDB就是首选了。
缩写含义
DDL:数据库模式定义语言,关键字:create
DML:数据操纵语言,关键字:Insert、delete、update
DCL:数据库控制语言 ,关键字:grant、remove
DQL:数据库查询语言,关键字:select
having函数
HAVING子句在聚合后对组记录进行筛选,HAVING在查询语句中必须依赖于GROUP BY
Redis
redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
Memcache与Redis的区别都有哪些?
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型 Memcache对数据类型支持相对简单。 Redis有复杂的数据类型。
3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
为什么redis需要把所有数据放到内存中
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。
如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
和关系型数据库中的事务相比,在Redis事务中如果有某一条命令执行失败,其后的命令仍然会被继续执行。
Redis 分布式
redis支持主从的模式。原则:Master会将数据同步到slave,而slave不会将数据同步到master。Slave启动时会连接master来同步数据。
这是一个典型的分布式读写分离模型。我们可以利用master来插入数据,slave提供检索服务。这样可以有效减少单个机器的并发访问数量
Redis 常见的性能问题都有哪些?如何解决?
Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内